
Summary #
The goal of this computer vision project is to build an image classifier for the identification of 120 different dog breeds. The model can be accessed through a Streamlit web app, and takes an image of a dog and returns a bar chart with the probabilities of the dog breed to show the model’s confidence in the dog breed determination. The dataset comes from the 2011 Stanford Dogs dataset which can also be found on Kaggle. The accuracy of the classification model on the test dataset is almost 80%. You may try it out yourself at the link below.
Dog breed image classification web app • Streamlit
Introduction #
This project was originally one of the capstone projects for the Machine Learning Zoomcamp bootcamp I finished a few months ago, and is saved in a repository on my personal GitHub website, where there is a lot more detail about the model generation.
The original dataset used to generate the classifier was retrieved from the ImageNet Dogs Dataset for Fine-grained Visual Categorization website. As mentioned on the website, the dataset contains 20,850 images of 120 breeds of dogs from around the world, and was built using images and annotations from the ImageNet dataset, which was devised for the task of fine-grained image categorization. This dataset can also be found on Kaggle at Stanford Dogs Dataset. The dataset was split into training, validation and testing datasets containing respectively 70%, 15% and 15% of the data.
Model training #
The model makes use of the convolutional layers of the Xception pre-trained convolution neural network (CNN) model which was chosen for its modest model size and fast inference time. The original top dense layers are removed and are re-generated using the images from the Stanford Dogs Dataset, a process called transfer learning. In the training process, the photos in the dataset were also randomly rotated by 10 degrees in both directions and flipped horizontally to increase the variability of the data in the training set, a technique called data augmentation. More can be found in the developer guide article on transfer learning & fine-tuning on the Keras website that I used as an inspiration for this work.
Fine-tuning #
Model hyperparameter fine-tuning was accomplished using different values for the learning rate, the number of the additional, dense layers and the dropout rates. The learning rate determines the size of the steps the optimizer takes when updating the model’s weights during training. The dense layers allow the network to learn complex patterns and features from the data, potentially improving performance but also increasing the risk of overfitting. The dropout rate affects the network by randomly setting a fraction of input units to zero during training. This helps prevent overfitting by forcing the network to learn more robust features and reducing reliance on specific neurons.
The best values for the learning rate, the number of dense layers and the dropout rates are determined as those that maximize the accuracy and are saved to generate the final model. Since the training time wasn’t excessively long with the Nvidia GPU hardware provided on the Saturn Cloud compute resource I was using, I decided to increase the number of dog breeds in the training set to the full 120 breeds of the complete dataset. Even so, in the end the training took less than six hours.
Inference #
The project is accessible on the Streamlit Cloud Community, where you can upload an image of a particular dog breed and see the classifier identify the breed. The classifier on the testing dataset achieves an accuracy of almost 80%. It doesn’t guarantee that the classifier will correctly identify all dog breeds, but it should still achieve fairly good results. Here is an example of the app on a photo of a golden retriever taken from Unsplash.
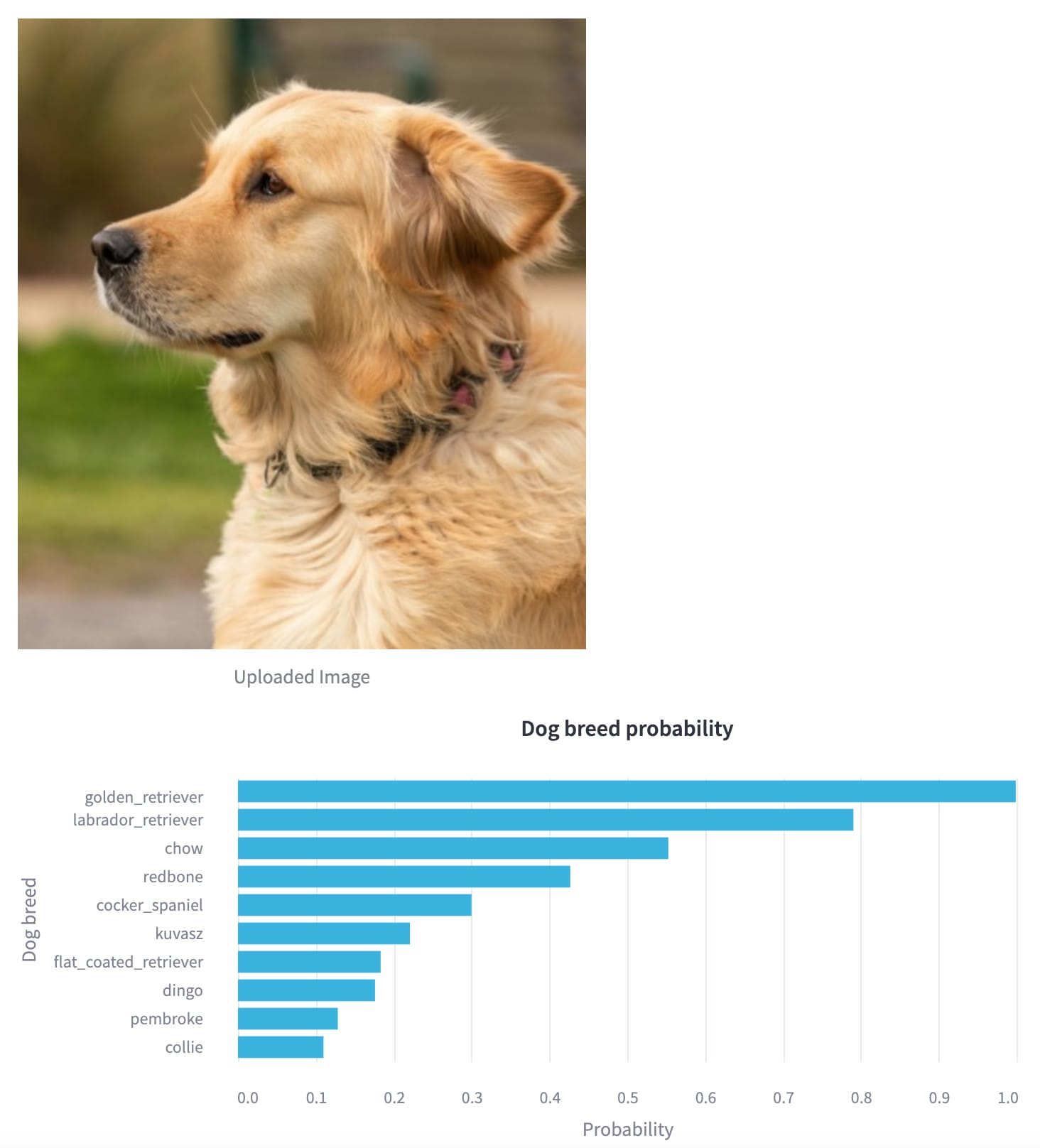
Classification of a golden retriever by the Streamlit web app.
Try it out yourself at the link below!
Dog breed image classification web app on Streamlit
Conclusions #
The Github code for the original project has been updated to include code for Streamlit deployment. Feel free to take a look at the specific code for this project here in my GitHub repository.
For the data analysis, the following software packages were used: TensorFlow (version 2.15.0), Scikit-Image (version 0.22.0), Pillow (version 10.2.0), Matplotlib (version 3.8.2), Streamlit (version 1.32.2) and Pandas (version 1.5.3).
